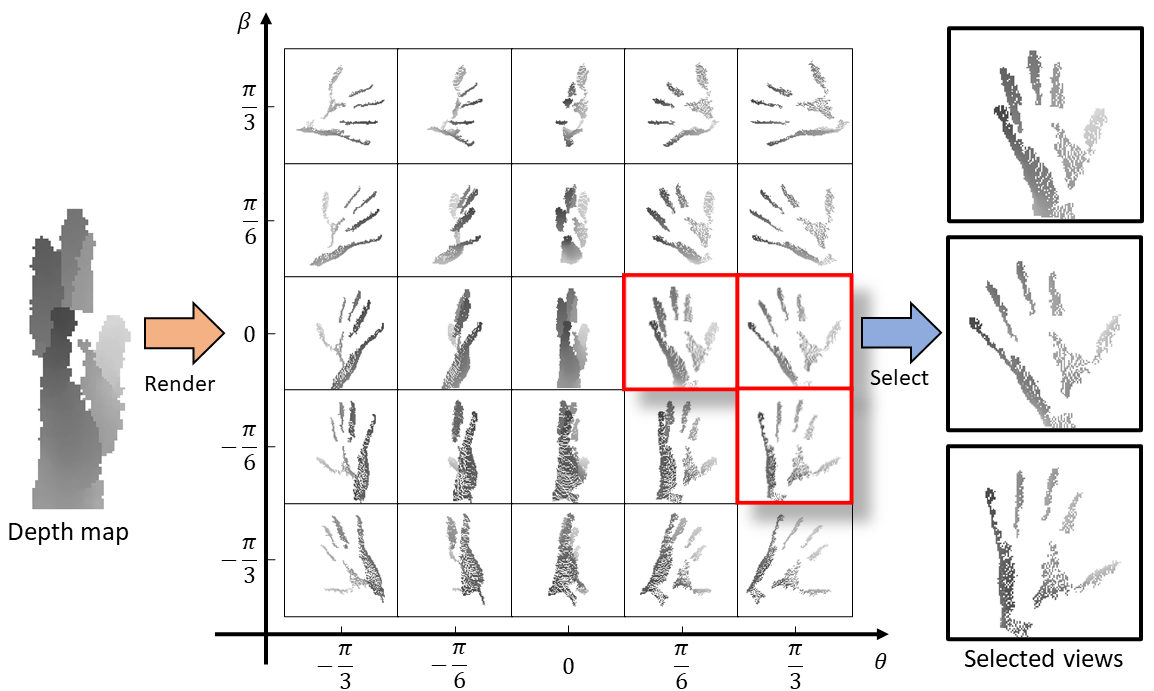
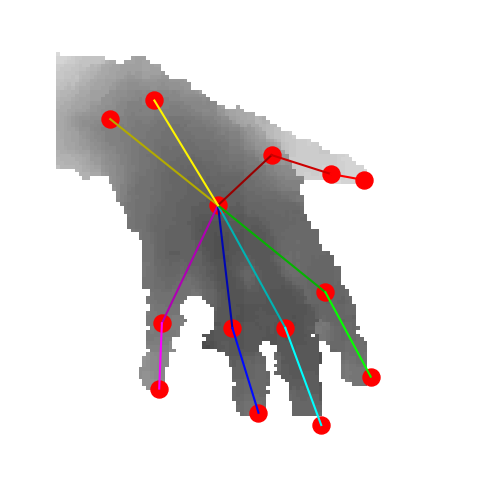
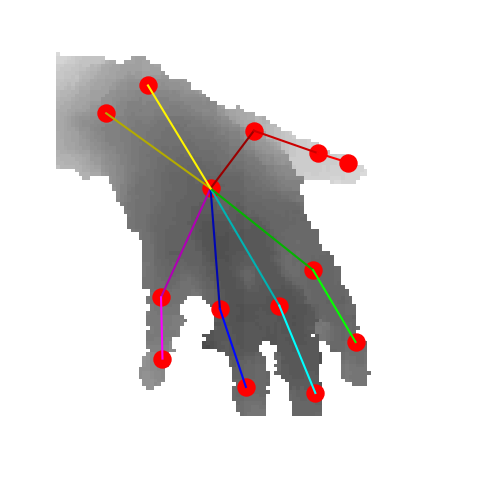
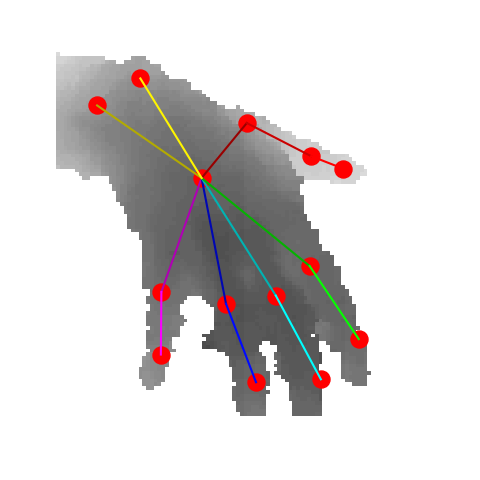
Illustration of view selection for 3D hand pose estimation. The view of the original depth image may not be suitable for pose estimation. We select suitable views for pose estimation from the uniformly sampled virtual views.
|
Jian Cheng1,2*
|
Yanguang Wan1,2*
|
Dexin Zuo1,2
|
Cuixia Ma1
|
Jian Gu3
|
|
Ping Tan3,4
|
Hongan Wang1
|
|
|
|
Illustration of view selection for 3D hand pose estimation. The view of the original depth image may not be suitable for pose estimation. We select suitable views for pose estimation from the uniformly sampled virtual views.
|
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications. However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.
|
|
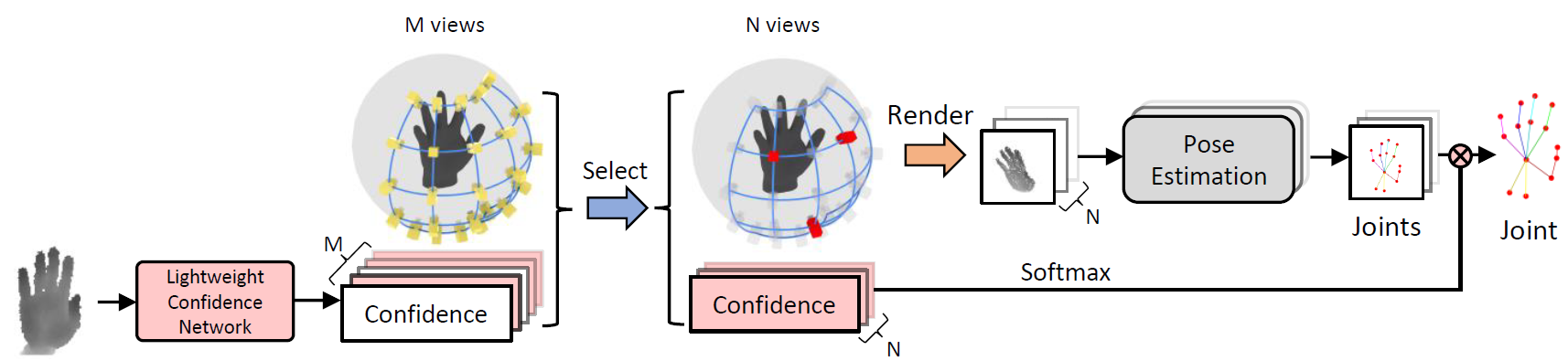
We first convert a depth image into 3D point clouds,
and uniformly set up candidate virtual views
on the spherical surface centered in the hand point clouds.
Then we calculate the confidence of each candidate virtual views
and select high-quality views accordingly.
A 3D pose estimation network then predicts the 3D hand pose
from views with top-N confidence, and finally fuses the pose
with regard to the confidence to achieve accurate 3D hand pose results.
|

|
J. Cheng, Y. Wan, D. Zuo, C. Ma, J. Gu, P. Tan, H. Wang, X. Deng, Y. Zhang
Efficient Virtual View Selection for 3D Hand Pose Estimation. AAAI, 2022. [Paper] [Bibtex] [Code] |
|
|
|
|
|
|
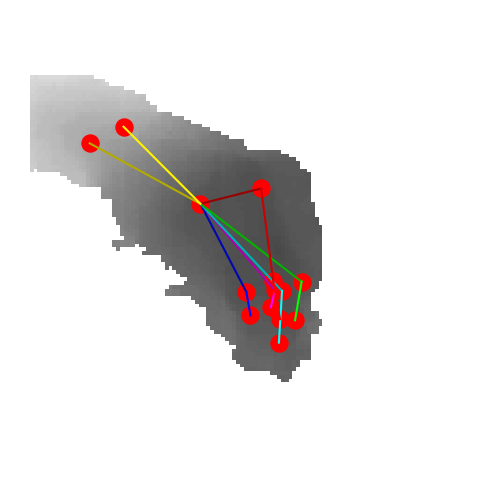
|
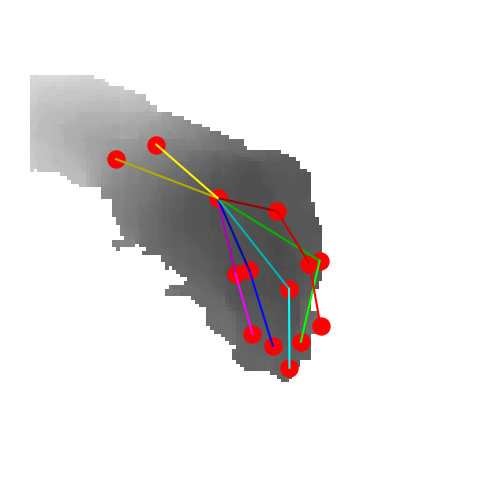
|
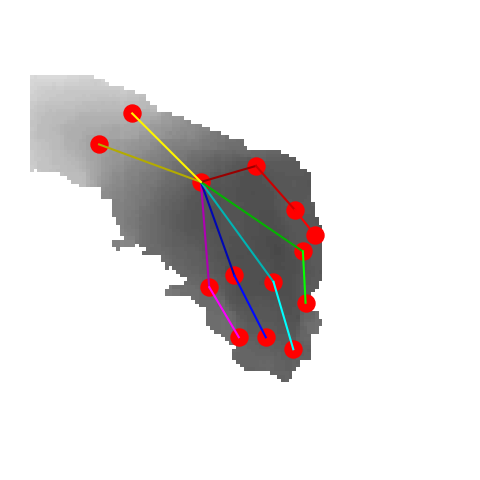
|
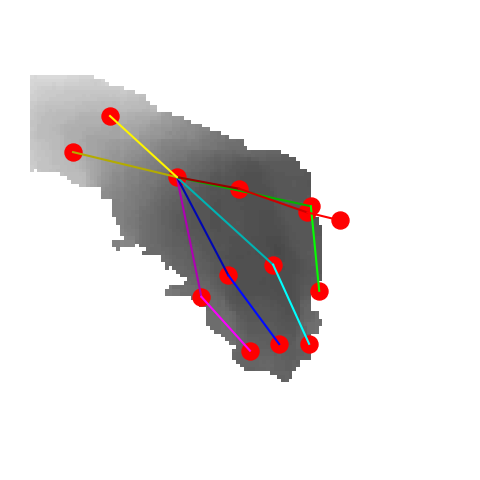
|
|
|
|
|
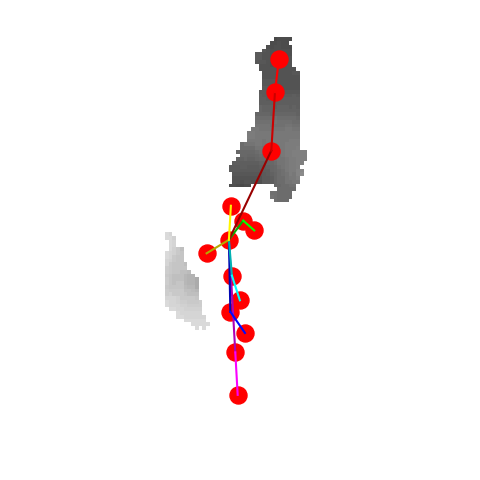
|
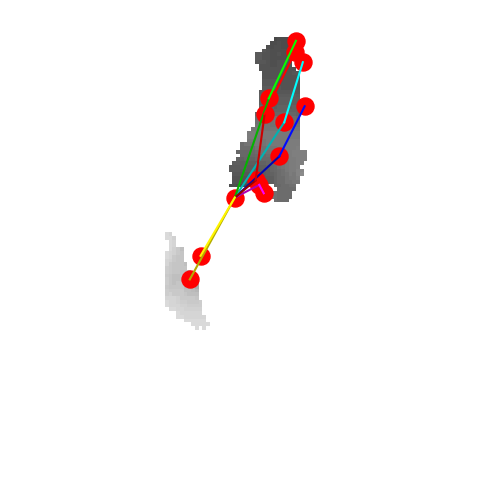
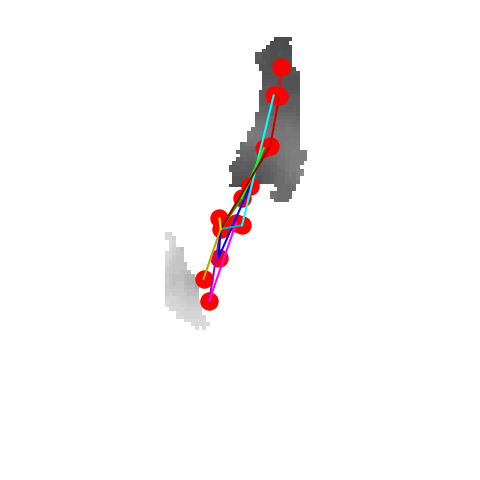
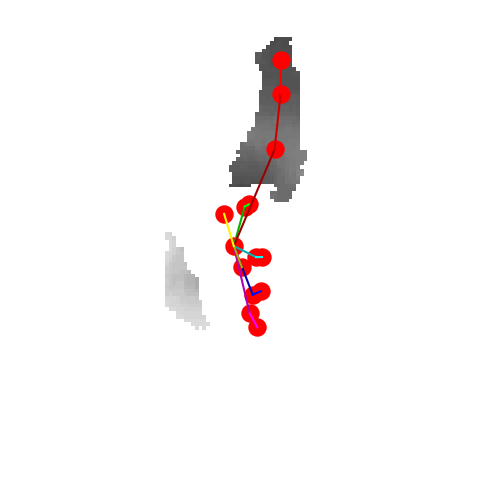
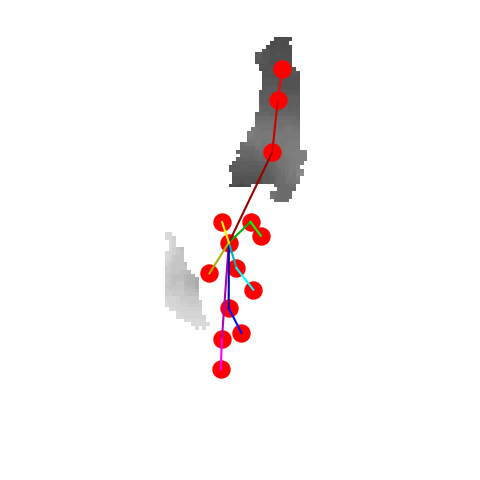
P2P |
V2V |
A2J |
Ours 25views |
Ground truth |

|
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (No. 62076061, No. 61473276, No. 61872346), Beijing Natural Science Foundation (4212029, L182052), and Newton Prize 2019 China Award (NP2PB/100047).
The websiteis modified from this template.
|